这代人的热情-MapReduce的工作原理学习(二)
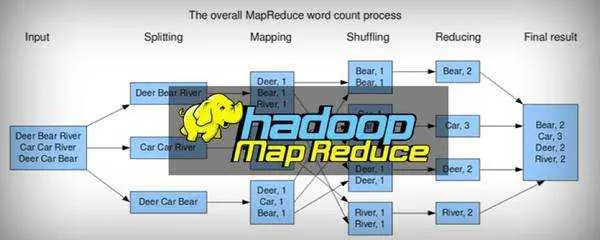
本篇笔记是完全对前一篇文章内容的补充,这代人的热情-MapReduce的工作原理学习(一)在前面的笔记中写到了MapReduce中重要的两个处理阶段,那就是Map和Reduce阶段嘛。我在网上看到了这一段有趣的解释部件间关系的说法,挺好记,很形象的说清楚了都是干啥的。NameNode是HDFS的老大。DataNode是HDFS的小弟。SecondaryNameNode是NameNode的助理。Re
本篇笔记是完全对前一篇文章内容的补充,这代人的热情-MapReduce的工作原理学习(一)在前面的笔记中写到了MapReduce中重要的两个处理阶段,那就是Map和Reduce阶段嘛。我在网上看到了这一段有趣的解释部件间关系的说法,挺好记,很形象的说清楚了都是干啥的。NameNode是HDFS的老大。DataNode是HDFS的小弟。SecondaryNameNode是NameNode的助理。Re

在前一篇笔记中,提到了Hadoop 2.x在CentOS 6.9和Windows下的伪分布式部署。有了上一篇的基础,就可以在Linux或者Windows上搭建一个伪分布式的Hadoop了,继续捣鼓。这篇依旧是我的笔记,因为时间跨度大,本文是我的一系列文章,我直接或间接的引用了多篇网络文章的解决办法,用于解决本文实践中遇到的问题,时间过于仓促,并没有完全标明引用地址,再次表示感谢。最好配着官方的文档